Getting Historical Stock Data with Selenium and Beautiful Soup
Introduction
Now that I have a real job, it’s time that I start thinking about my financial future. I’ve been reading, “The Intelligent Asset Allocator” by William Bernstein and he pointed out that finding stocks which are uncorrelated can help reduce risk. I thought that this was an interesting idea and wanted to look at some of the data. I was upset to find that I couldn’t just download a csv with the historical data for all of Vangaurd’s funds. I didn’t want to go through and download each of them individually from NASDAQ’s database so I thought I’d turn to python to help me automate this process. In this discussion I’ll walk you through how I used Vangaurd tickers to extract historical stock data.
Now as a disclaimer, I think that the only purpose of financial forcasting is to demonstrate what a nobel profession astrology is, so don’t use any of this to try and predict the market. Also, remember that historical behaviour is not the best indicator of future behaviour, all of this is purely pedantic. On a long enough time scale all stocks become quite correlated.
Getting the Historical Data
With the stock tickers in hand we can head over to NASDAQ’s historical data site and start exploring some of these funds. This nice site allows you to download a csv for up to 10 years of historical data. Let’s walk through using Selenium to do this. First, we need to get to the website.
driver = webdriver.Firefox(profile)
# Get the stocks website
site = 'http://www.nasdaq.com/symbol/' + ticker + '/historical'
driver.get(site)I use a ticker variable to store which stock I want to access. In the final code we’ll step through all tickers in our list but for now just assume it’s something like ‘VDAIX’. This code creates a Firefox webdriver that we can use to navigate and manipulete the website “site”.
Now we need to select the historical data that we are interested in. There is a drop down menue which we can step through to select the point of interest with the following code:
# Choose 10 year data from a drop down
data_range = driver.find_element_by_name('ddlTimeFrame')
for option in data_range.find_elements_by_tag_name('option'):
if option.text == '10 Years':
option.click()
breakWe begin by extracting the select box and storing it in the data_range variable. Next we step through each option tag in this field and look for the one that is named ‘10 Years’. When we find it we click on it to select the 10 year data range and break out of our loop.
Lastly we need to download the data.
# Click to Download Data
driver.find_element_by_id('lnkDownLoad').click()However, this causes some problems. Firefox wants to check and make sure that we actually want to download this file. To get around this we can configure our webdriver instance so that it doesn’t worry about checking certain files.
# To prevent download dialog box in selenium
profile = webdriver.FirefoxProfile()
profile.set_preference('browser.download.folderList', 2)
profile.set_preference('browser.download.manager.showWhenStarting', False)
profile.set_preference('browser.download.dir', '/Data/Vangaurd')
profile.set_preference('browser.helperApps.neverAsk.saveToDisk', "text/plain, application/vnd.ms-excel, text/csv, application/csv, text/comma-separated-values, application/download, application/octet-stream, binary/octet-stream, application/binary, application/x-unknown")
# Setup Webdriver
driver = webdriver.Firefox(profile)Here we tell Firefox that we don’t want to see a dialogue box and moreover you can download any type of file in our aproved list. Now if we put it all together we can extract the historical data for any ticker in our list!
def pull_nasdaq_data(tickers, save_path, removal_path):
""" This method pulls 10 year historical data from NASDAQ's website.
It stores it in a CSV located in save_path
Args:
tickers: (list[String]) List of tickers to lookup on NASDAQ
save_path: (String) Path to where you want the files saved
removal_path: (String) Path to downloads folder to cleanup downloaded files
Returns:
VOID: Side effect saves off csv files of NASDAQ Data
"""
# To prevent download dialog box in selenium
profile = webdriver.FirefoxProfile()
profile.set_preference('browser.download.folderList', 2) # custom location
profile.set_preference('browser.download.manager.showWhenStarting', False)
profile.set_preference('browser.download.dir', '/Data/Vangaurd')
profile.set_preference('browser.helperApps.neverAsk.saveToDisk', "text/plain, application/vnd.ms-excel, text/csv, application/csv, text/comma-separated-values, application/download, application/octet-stream, binary/octet-stream, application/binary, application/x-unknown")
# Setup Webdriver
driver = webdriver.Firefox(profile)
popup = True # Will there be a popup?
for ticker in tickers:
# Get the stocks website
site = 'http://www.nasdaq.com/symbol/' + ticker + '/historical'
driver.get(site)
# Choose 10 year data from a drop down
data_range = driver.find_element_by_name('ddlTimeFrame')
for option in data_range.find_elements_by_tag_name('option'):
if option.text == '10 Years':
option.click()
break
time.sleep(10)
# Click to Download Data
driver.find_element_by_id('lnkDownLoad').click()
# Open the file from the downloads folder
time.sleep(10) # Wait for file to download
data = pd.read_csv('~/Downloads/HistoricalQuotes.csv')
# Rename and save the file in the desired location
file_loc = save_path + ticker + '.csv'
data.to_csv(file_loc, index=False)
# Delete the downloaded file
os.remove(removal_path)
print "Downloaded: ", ticker
# Wait for the next page to load
time.sleep(20)
rm_path = '../../Downloads/HistoricalQuotes.csv'
save_path = '~/Data/Vangaurd/'
pull_nasdaq_data(tickers, save_path, rm_path)Looking for Correlations
Now we finally get to the fun stuff. Looking for correlations between different mutual funds. For the sake of analysis let’s assume that we currently have a portfolioo consisting of four Vangaurd mutual funds, Vangarud 500 Index Fund (VFINX), Vangaurd Samll Cap Index Fund (NAESX), Vangarud Total Bond Market Index Fund (VBMFX), and Vanguard Total Inernational Stock Index (VGTSX). If we want to look at good potential stocks for diversification we might try and find funds which are the least correlated with ones we possess. We can do taht with the following code snippet.
funds_of_interest = ['VFINX_Close', 'NAESX_Close', 'VBMFX_Close', 'VGTSX_Close']
balance = []
corr = []
correlation = data.corr()
for fund in funds_of_interest:
balance.append(correlation[fund].idxmin())
corr.append(correlation[fund].min())
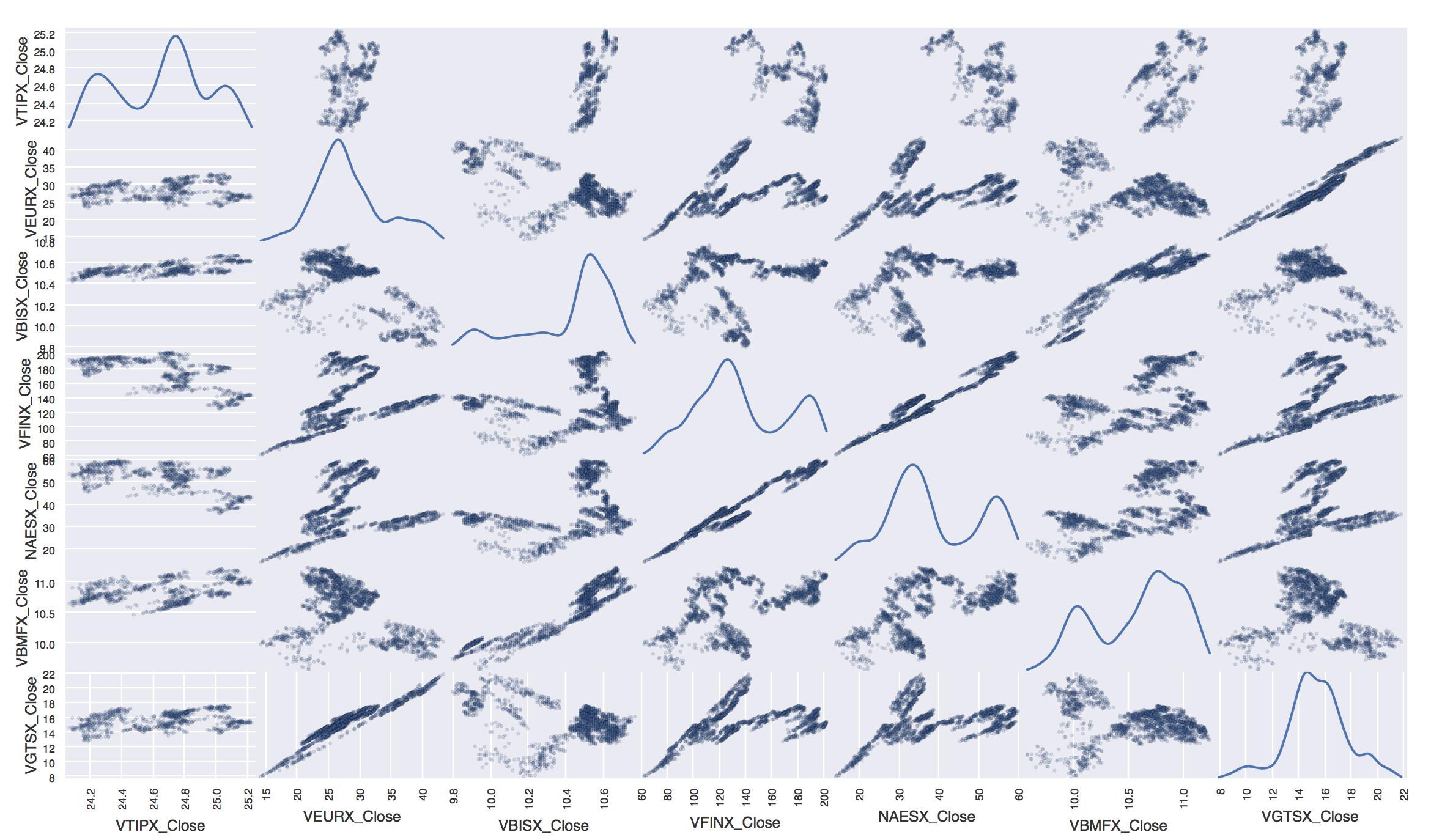
We’ve now found the set of stocks least correlated with my current asset mix. The results are summarized in the following Table:
| Fund in Portfolio | Least Correlated Fund | Correlation |
|---|---|---|
| VFINX | VTIPX | -.64 |
| NAESX | VTIPX | -.558 |
| VBMFX | VEURX | -.43 |
| VGTSX | VBISX | -.38 |
What we find is that US Bonds and securities are least correlated with US/international based mutual funds. We also find that the European stock index is least correlated with the total bond market index. These results agree with the intuition that bonds and stocks will behave very differently and provide a good asset balance.
Finally, I like to try and visualize what is going on here so I plotted a scatter plot matrix of the funds in my current mix and their least correlated companions.
pd.tools.plotting.scatter_matrix(data[balance + funds_of_interest], alpha=0.2, figsize=(20, 20), diagonal='kde')