How to Make a GPT2 Twitter Bot

Introduction
I love generative models. There is something magical about showing a machine a bunch of data and having it draw a picture or write a little story in the same vein as the original material. What good are these silly little models if we can’t share them with others right? This is the information age after all. In this post we’ll:
-
Walk through setting up a Twitter bot from scratch
-
Train one of the most cutting edge language models to generate text for us
-
Use the twitter API to make your bot tweet!
When you’re done with the tutorial you’ll be able to create a bot just like this one which tweets out generated proverbs. All code for this project can be found in this repository. Let’s get started : ).
Appeal to Reader
If you pay for Medium, or haven’t used your free articles for this month, please consider reading this article there. I post all of my articles here for free so everyone can access them, but I also like beer and Medium is a good way to collect some beer money : ). So please consider buying me a beer by reading this article on Medium.
Setup
This tutorial will use Python3. We will be using the gpt2-simple library to train our model. It relies on tensorflow.contrib which was removed in tensorflow 2.0 so you’ll need to use an earlier version : /. Sorry about that. To make things easy I’ve put together a docker container and Makefile for easy running in the repository. You can load up a working environment to play in by building the docker container:
make build
then running:
make run
If Jupyter is more your style you can also do
make run-jupyter
just notice that the port is set to 8989 instead of the usual 8888.
Setting up Twitter
Setting up a bot with Twitter just requires you to apply for a developer account and link the credentials with whatever code you want to run. The below section walks through in detail setting up a developer account. It’s kind of boring so if you’ve already got one just skip to the next section.
Start by logging into Twitter then heading to their developer site. You should see something like the below image.
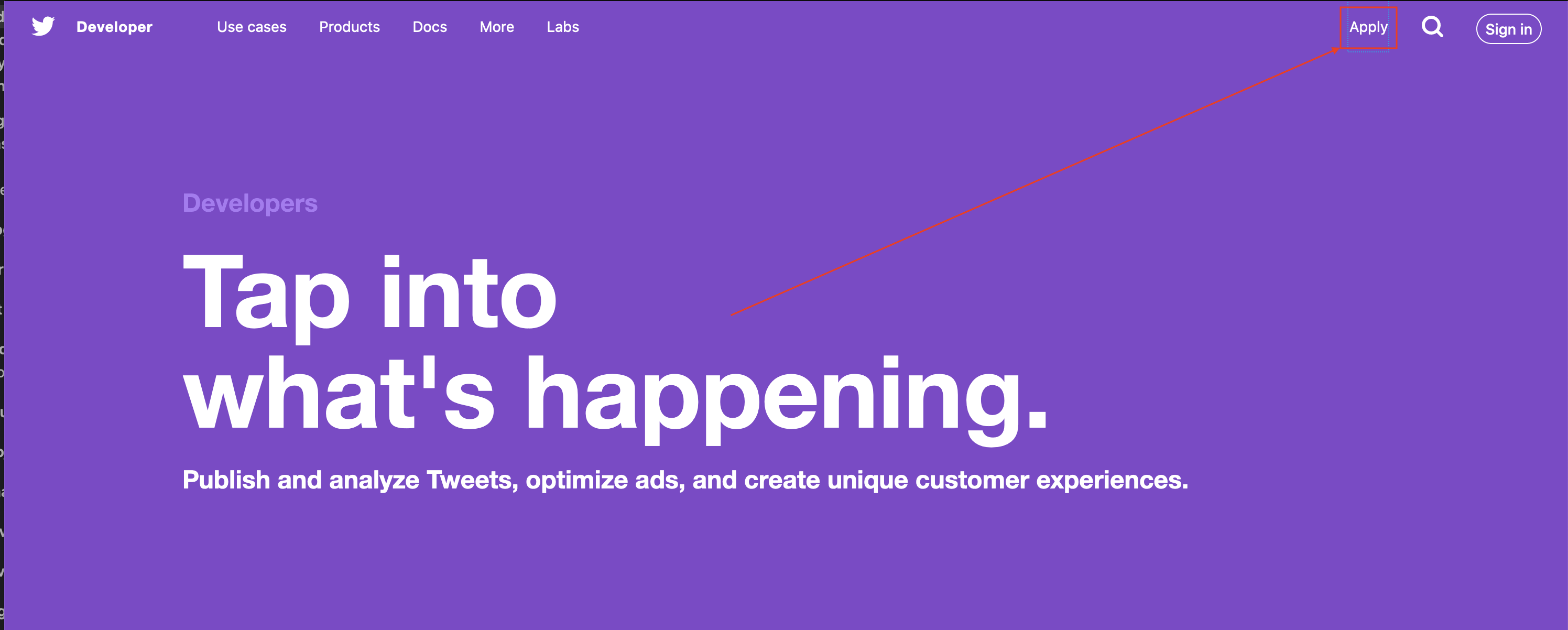
Click the Apply button in the top right. This will take you to a new page where you need to click on “apply for a developer account.”
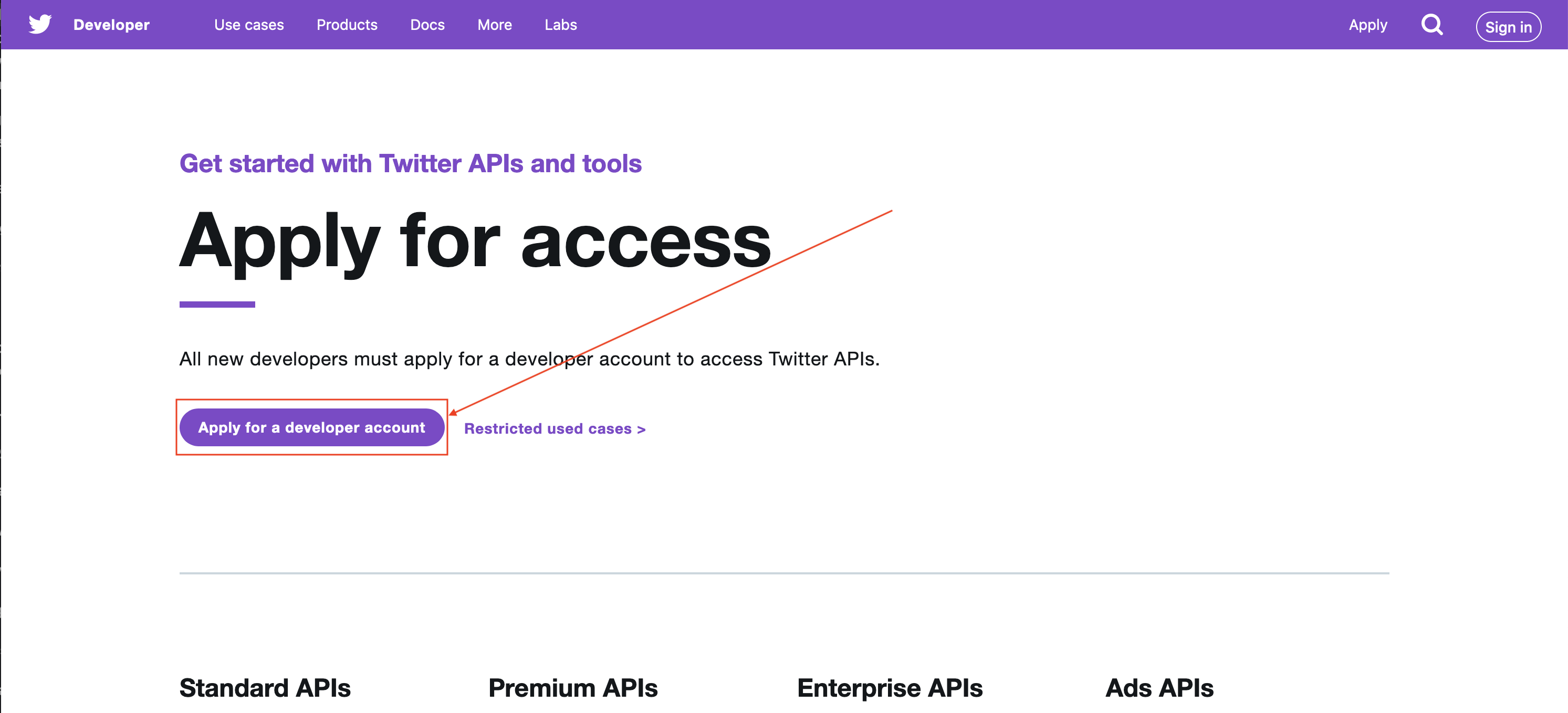
This will take you to a page asking what you’re going to be doing with the developer account. We’re making a bot so choose that, but if you’re feeling spicy and want to do other things mark those as well.
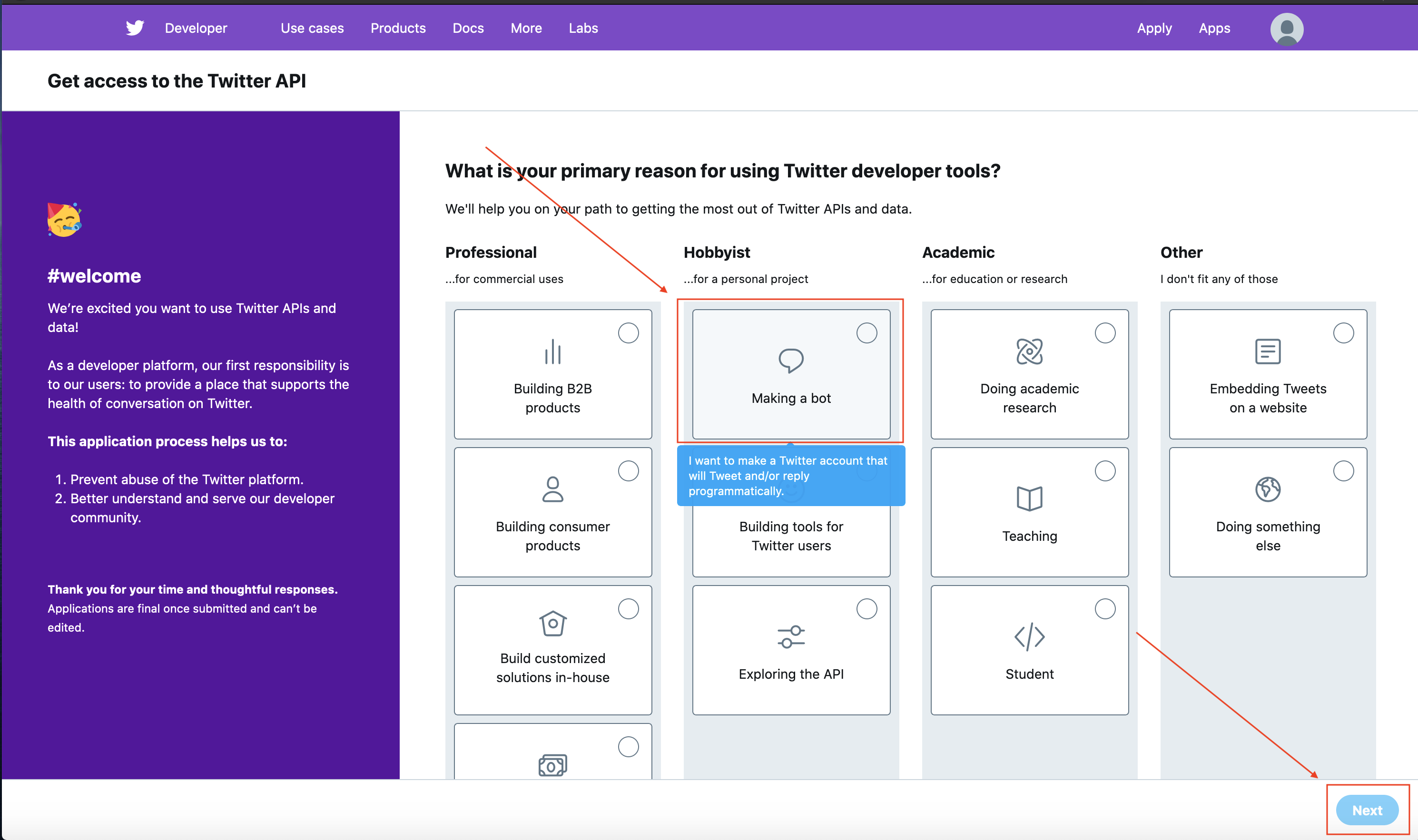
Then fill in all the information on the next page and add a phone number.
The last page involves a two questions which need to be answered. Below I outline my response to each question which got approval. Feel free to copy them, if you intend to use this bot as I do, just to make tweets sometimes. You can mark the other ones as not relevant for this bot.
In English, please describe how you plan to use Twitter data and/or APIs. The more detailed the response, the easier it is to review and approve.
“I plan to build a small bot which will use GPT2, a Markov Chain, or some variation of an RNN to make simple tweets daily about a given topic. The purpose is to just share some of the fun generated text that these models make via the Twitter platform.”
Will your app use Tweet, Retweet, like, follow, or Direct Message functionality?
“The app will use the tweepy Python library to update the bot’s twitter status with a tweet daily. The Python script will be run from a cron job on my computer and will only use the Tweet functionality.”
You’ll need to wait for them to approve your application. At this point we have the pleasure of filling out another form describing our App! Navigate to the App page by clicking on your name and then the App drop down field.
Click create an App.
Fill in yet another form …
Once all of this is filled out and submitted you should be good to go. You’ll see your new app in the App page. When you click on details you can get your API keys. You can only view your access tokens one time so make sure to write them down. I stored mine in a JSON file. This made it easy for me to access these tokens programmatically.
{"consumer_key": aaaa
"consumer_secret": "bbbb"
"access_key": "cccc"
"access_secret": "dddd"}
That’s it! We are finally ready to write some code!
Get Some Data
I’m going to have my Twitter bot write funny proverbs. You can find the data I used to train my model here . For yours, see if you can find a data set where the main ideas are short and there is a decent bit of data. Some ideas might be Kanye West tweets, the tweets of current and former presidents, or even magic cards.
The GPT2 simple model we will be using acts on a text file so all we need to do is compile whatever text source we are interested in into a single text file. One thing I like to do while training GPT2 is add separators between different sections which don’t show up in the text. For example, you could just put all of the book of proverbs into one file, or you could separate each proverb with “\n==========\n”. Then the model can learn where the proverbs begin and end and you can parse the output more easily. I’ve formatted the proverbs text the way I like where there is a “\n==========\n” delimiting the end of each proverb and all extra characters have been removed.
Build the Brain
Making a world class generative model for text has never been easier. When I made my first generative model I had to write a ton of code to build the model, train the model, extract reasonable predictions from the model, etc. Now we can do a little transfer learning on GPT2 and get better results than we could have dreamed of a few years ago.
Max Woolf created an amazing library which makes it super easy to fine tune GPT2. We’re going to take all of his excellent work and use that interface for training. The below 30 lines of code are all that’s needed to fine tune a best in class generative model. The gpt2_simple finetune function takes in a few parameters which are worth explaining.
import gpt_2_simple as gpt2
# The name of the pretrained GPT2 model we want to use it can be 117M, 124M, or 355M
# 124M is about as big as I can fit on my 1080Ti.
model_name = "124M"
# Download the model if it is not present
if not os.path.isdir(os.path.join("models", model_name)):
print(f"Downloading {model_name} model...")
gpt2.download_gpt2(model_name=model_name)
# Start a Tensorflow session to pass to gpt2_simple
sess = gpt2.start_tf_sess()
# Define the number of steps we want our model to take we want this to be such that
# we only pass over the data set 1-2 times to avoid overfitting.
num_steps = 100
# This is the path to the text file we want to use for training.
text_path = "proverbs.txt"
# Pass in the session and the
gpt2.finetune(sess,
text_path,
model_name=model_name,
steps=num_steps
)
gpt2.generate(sess)-
session The session is just the current Tensorflow session
-
dataset This is the path to a text file to load in and use for training, more on this later.
-
model_name The name of the GPT2 model to use can be 117M, 124M, or 355M. 124M works well on my 1080Ti GPU.
-
steps The number of steps for the model to take. This number should be high enough to step through your whole data set at least once but not so high that you over fit. When fine tuning GPT2 on a relatively small data set I like to do one to two epochs. Then I test to make sure that what it generates wasn’t directly from the training set.
We can calculate the number of steps by looking at the total number of words in the text using the wc utility:
wc Data/proverbs_clean.txt
yields
1816 15984 93056 Data/proverbs_clean.txt
We can see that this file has 1,816 lines, 15,984 words, and 93,056 characters. The default number of words passed to the model in a step is set with the sample_length parameter and is 1023 by default. So 15984 / 1023 = 15.6. So every 16 steps we go through all of the data one time. That means we should probably train our model for somewhere between 33 and 66 steps. To avoid over fitting.
To generate new text given the model we can use the gpt2_simple.generate function like so:
sess = gpt2.start_tf_sess()
gpt2.load_gpt2(sess, checkpoint_dir=checkpoint_dir)
text = gpt2.generate(
sess,
checkpoint_dir=checkpoint_dir,
length=length,
temperature=temperature,
destination_path=destination_path,
prefix=prefix,
return_as_list=True
)Again let’s break down these arguments.
-
sess is the tensorflow session we want to use
-
temperature is and value greater than 0 I like to play around between .8 and 2. The lower the temperature the more consistent and predictable your
-
outputs the higher the temperature the more wild, fun, and possibly nonsensical they will be.
-
destination_path is a path to where you want the text to be saved. If you just want to return it inline make this None
-
prefix is a fun one. It can be a string of text that is used to seed the model. So if you started with “thou shall not” then the model will write the next words as if it had started with “thou shall not.”
-
return_as_list will cause the function to return the text instead of just printing it out.
Running that code we can generate some proverbs!
for he that taketh away his beret also with food, and as a disorderly child, so hath a man a very strange prayer
==========
for though it seem good to us to be taken, yet a man that hath it in his heart never cometh out of it
==========
he that hath his substance with him seeketh out knowledge and hath neither toy with his heart
==========
for a stranger cometh when i talk with him, and delivereth him, so that i may give to him even as the blood I drink, and a spare change my food
Build the Bot
We have data , a model that has been trained on our data, and a Twitter developer account all that is left is to link them together. Our bot needs to do 3 things.
-
Authenticate with the Twitter API
-
Generate a proverb
-
Post that proverb to Twitter.
Luckily Tweepy makes the first and third part super easy and we’ve already done the second!
Authentication
To start we need to get our credentials into Python. As I mentioned earlier I stored mine in a little JSON file so that it was super easy to load it in with Python.
# Parse the credentials for the twitter bot
with open("twitter.json", "r") as json_file:
twitter_creds = json.load(json_file)
# Set the credentials based on the credentials file
CONSUMER_KEY = twitter_creds['consumer_key']
CONSUMER_SECRET = twitter_creds['consumer_secret']
ACCESS_KEY = twitter_creds['access_key']
ACCESS_SECRET = twitter_creds['access_secret']With all of these credentials we can authenticate with the Twitter API using Tweepy.
# Authenticate with the Twitter API
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_KEY, ACCESS_SECRET)
api = tweepy.API(auth)Text Generation
Now we can generate new text using the code we wrote earlier. I packaged all of that into a little function called generate_text. After generating the text we want to make sure we don’t grab any spans of text longer than 280 characters, because that’s Twitter’s tweet limit.
# Generate some text
generated_text = generate_text(checkpoint_dir, length, temperature, None, prefix)
# Parse out all "sentences" by splitting on "\n-------\n"
split_text = generated_text.split("\n-------\n")
# Filter out all examples which are longer than 140 characters
valid_text = [x for x in split_text if len(x) <= 280]Tweet
Tweeting is just two lines now! Select a proverb at random, then update the bots status using Tweepy!
tweet = np.random.choice(valid_text, 1)
api.update_status(tweet[0])And there it is!
Wrapping Up
We’ve got code to generate tweets in the style of biblical proverbs, and the technology to do this with any text corpus! I usually just schedule a cron job on my server to run this once or twice a day. I’ve included a Makefile in the repository to make it easy to have the bot tweet with one command. Simply run:
make CHECKPOINT_DIR="deepproverbs" TWITTER_CREDS="twitter.json" tweet
I wrapped all of the code we’ve written today into some nice click functions so it should be easy to run from the command line.