Translate Any Two Languages in 60 Lines of Python

Introduction
I remember when I built my first seq2seq translation system back in 2015. It was a ton of work from processing the data to designing and implementing the model architecture. All that was to translate one language to one other language. Now the models are so much better and the tooling around these models leagues better as well. HuggingFace recently incorporated over 1,000 translation models from the University of Helsinki into their transformer model zoo and they are good. I almost feel bad making this tutorial because building a translation system is just about as simple as copying the documentation from the transformers library.
Anyway, in this tutorial, we’ll make a transformer that will automatically detect the language used in text and translate it into English. This is useful because sometimes you’ll be working in a domain where there is textual data from many different languages. If you build a model in just English your performance will suffer, but if you can normalize all the text to one language you’ll probably do better.
Appeal to Reader
If you pay for Medium, or haven’t used your free articles for this month, please consider reading this article there. I post all of my articles here for free so everyone can access them, but I also like beer and Medium is a good way to collect some beer money : ). So please consider buying me a beer by reading this article on Medium.
💾 Data 💾
To explore how effective this approach is I needed a dataset of small text spans in many different languages. The Jigsaw Multilingual Toxic Comment Classification challenge from Kaggle is perfect for this. It has a training set of over 223k comments labeled as toxic or not in English and 8k comments from other languages in a validation set. We can train a simple model on the English training set. Then use our translation transformer to convert all other texts to English and make our predictions using the English model.
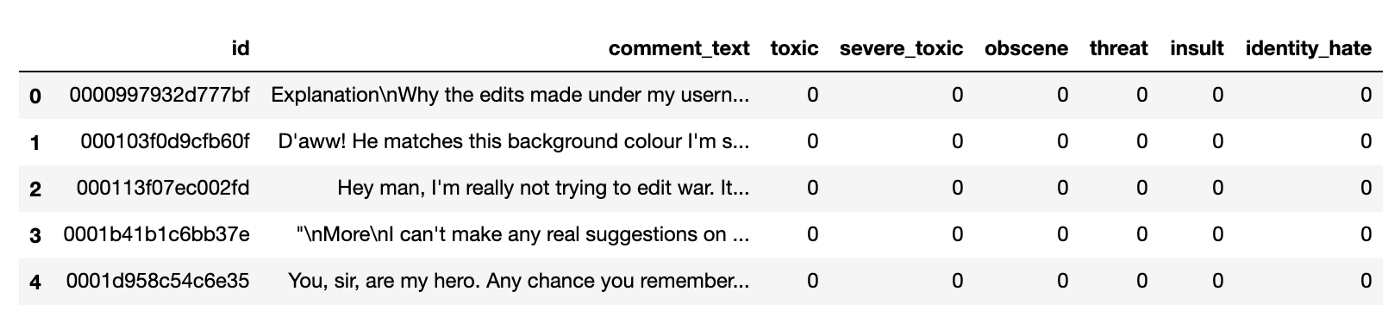
Taking a look at the training data we see that there are about 220K English* example texts labeled in each of six categories.
The place where things get interesting is the validation data. The validation data contains no English and has examples from Italian, Spanish, and Turkish.

🕵️ Identify the Language 🕵️️
Naturally, the first step toward normalizing any language to English is to identify what our unknown language is. To do that we turn to the excellent Fasttext library from Facebook. This library has tons of amazing stuff in it. The library is true to its name. It really is fast. Today we’re only going to use its language prediction capabilities.
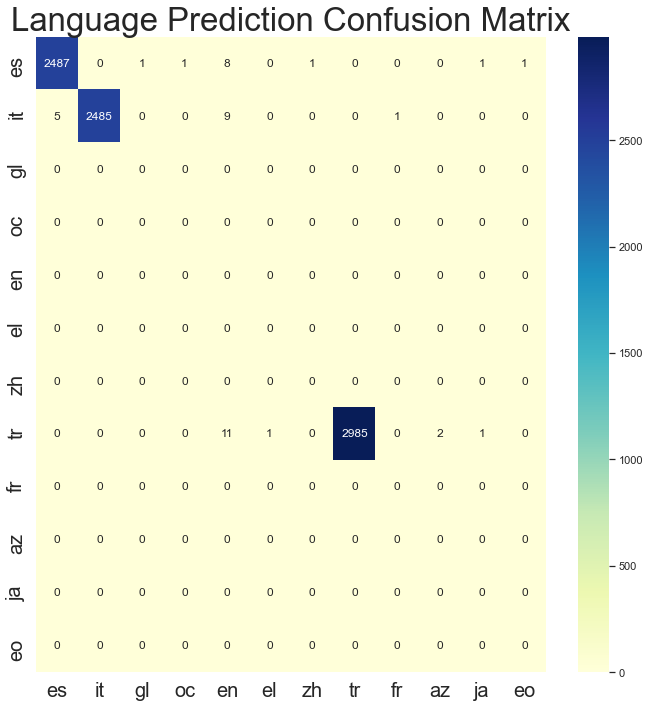
It’s that simple to identify which language an arbitrary string is. I ran this over the validation set to get a sense of how well the model did. I was, quite frankly, astonished at its performance out of the box. Of the 8,000 examples, Fasttext only misclassified 43. It also only took 300ms to run on my MacbookPro. On both accounts, that’s pretty bananas 🍌. If you look closer you’ll notice that in some of the Spanish mispredictions it predicted Galician or Occitan. These are languages spoken in and around Spain and have Spanish roots. So the mispredictions in some cases aren’t as bad as we might think.
🤗 Transformers 🤗
Now that we can predict which language a given text is, let’s see about translating it. The transformers library from HuggingFace never ceases to amaze me. They recently added over a thousand translation models to their model zoo and every one of them can be used to perform a translation on arbitrary texts in about five lines of code. I’m stealing this almost directly from the documentation.
lang = "fr"
target_lang = "enmodel_name = f'Helsinki-NLP/opus-mt-{lang}-{target_lang}'# Download the model and the tokenizer
model = MarianMTModel.from_pretrained(model_name)
tokenizer = MarianTokenizer.from_pretrained(model_name)
# Tokenize the text
batch = tokenizer.prepare_translation_batch(src_texts=[text])
# Make sure that the tokenized text does not exceed the maximum
# allowed size of 512
batch["input_ids"] = batch["input_ids"][:, :512]
batch["attention_mask"] = batch["attention_mask"][:, :512]# Perform the translation and decode the output
translation = model.generate(**batch)
tokenizer.batch_decode(translation, skip_special_tokens=True)Basically, for any given language code pair you can download a model with the name Helsinki-NLP/optus-mt-{lang}-{target_lang} where lang is the language code for the source language and target_lang is the language code for the target language we want to translate to. If you want to translate Korean to German download the Helsinki-NLP/optus-mt-ko-de model. It’s that simple 🤯!
I make a slight modification from the documentation where I window the input_ids and the attention_mask to only be 512 tokens long. This is convenient because most of these transformer models can only handle inputs up to 512 tokens. This prevents us from erroring out for longer texts. It will cause problems though if you’re trying to translate very long texts, so please keep this modification in mind if you’re using this code.
SciKit-Learn Pipelines
With the model downloaded let’s make it easy to incorporate this into a sklearn pipeline. If you’ve read any of my previous posts you’re probably aware that I love SciKit Pipelines. They are such a nice tool for composing featurization and model training. So with that in mind let’s create a simple transformer that will take in any textual data, predict its language, and translate it. Our goal is to be able to construct a model which is language-agnostic by running:
from sklearn import svm
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.pipeline import Pipelineclassifier = svm.LinearSVC(C=1.0, class_weight="balanced")
model = Pipeline([
('translate', EnglishTransformer()),
('tfidf', TfidfVectorizer()),
("classifier", classifier)
])This pipeline will translate each datapoint in any text to English, then create TF-IDF features, and then train a classifier. This solution keeps our featurization in line with our model and makes deployment easier. It also helps prevent features from getting out of sync with your model by doing the featurizing, training, and predicting all in one pipeline.
Now that we know what we are working toward let’s build this EnglishTransformer! Most of this code you will have already seen above we’re just stitching it together. 😄
-
Lines 15–18 — Make sure the fasttext model is downloaded and ready to use. If it isn’t it downloads it to temp
/tmp/lid.176.bin. -
Line 23 — Establishes the language codes that are translatable with the Helsinki ROMANCE model. That model handles a bunch of languages really well and will save us a bunch of disk space because we don’t have to download a separate model for each of those languages.
-
Lines 26–29 — Define which languages we will translate. We want to create an allowed list of languages because each of these models is about 300MB so if we downloaded a hundred different models we’d end up with 30GB of models! This limits the set of languages so that we don’t run our system out of disk space. You can add ISO-639–1 codes to this list if you want to translate them.
-
Lines 31–37 — Define a function to perform the fasttext language prediction like we discussed above. You’ll notice we also filter out the\n character. This is because Fasttext automatically assumes this is a different data point and will throw an error if they are present.
-
Line 40— Defines the transformation and is where the magic happens. This function will convert a List of strings in any language to a List of strings in English.
-
Lines 47–49 — Check to see if the current string is from our target language. If it is we add it to our translations as is because it is already the correct language.
-
Lines 53–54 — Check to see if the predicted language can be handled by the Romance model. This helps us avoid downloading a bunch of extra language models.
-
Lines 55–64 — Should look familiar they are just the translation code from the hugging face documentation. This section downloads the correct model and then performs translation on the input text.
That’s it! Super straightforward and it can handle anything. Something to be aware of this code was written to be as readable as possible and is VERY slow. At the end of this post, I include a much faster version that batch predicts different languages instead of downloading a model for each data point.
🤑Results 🤑
We can now train and test our model using:
from sklearn import svm
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.pipeline import Pipelineclassifier = svm.LinearSVC(C=1.0, class_weight="balanced")
model = Pipeline([
('translate', EnglishTransformer()),
('tfidf', TfidfVectorizer()),
("classifier", classifier)
])
model.fit(train_df["comment_text"].tolist(), train_df["toxic"])
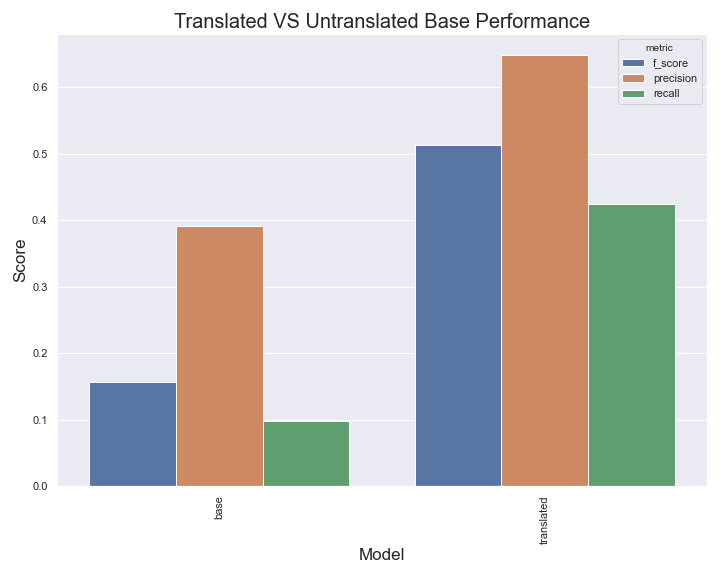
preds = model.predict(val_df["comment_text"])Training a simple TF-IDF model on the English training set and testing on the validation set gives us an F1 score for toxic comments of .15! That’s terrible! Predicting every class as toxic yields an F1 of .26. Using our new translation system to preprocess all input and translate it to English our F1 becomes .51. That’s almost a 4x improvement!
Keep in mind the goal here was simple translation not necessarily SOTA performance on this task. If you actually want to train a toxic comment classification model that gets good performance to fine-tune a deep transformer model like BERT.
If you enjoyed this post check out one of my other posts on working with text and SciKit-Learn. Thanks for reading! : )
Faster Transformer
As promised here is the code for a faster version of the English Transformer. Here we sort the corpus by predicted language and only load a model in once for each language. It could be made even faster by batch processing input using the transformer on top of this.
from typing import List, Optional, Set
from sklearn.base import BaseEstimator, TransformerMixin
import fasttext
from transformers import MarianTokenizer, MarianMTModel
import os
import requests
class LanguageTransformerFast(BaseEstimator, TransformerMixin):
def __init__(
self,
fasttext_model_path: str = "/tmp/lid.176.bin",
allowed_langs: Optional[Set[str]] = None,
target_lang: str = "en",
):
self.fasttext_model_path = fasttext_model_path
self.allowed_langs = allowed_langs
self.target_lang = target_lang
self.romance_langs = {
"it",
"es",
"fr",
"pt",
"oc",
"ca",
"rm",
"wa",
"lld",
"fur",
"lij",
"lmo",
"gl",
"lad",
"an",
"mwl",
}
if allowed_langs is None:
self.allowed_langs = self.romance_langs.union(
{self.target_lang, "tr", "ar", "de"}
)
else:
self.allowed_langs = allowed_langs
def get_language(self, texts: List[str]) -> List[str]:
# If the model doesn't exist download it
if not os.path.isfile(self.fasttext_model_path):
url = (
"https://dl.fbaipublicfiles.com/fasttext/supervised-models/lid.176.bin"
)
r = requests.get(url, allow_redirects=True)
open("/tmp/lid.176.bin", "wb").write(r.content)
lang_model = fasttext.load_model(self.fasttext_model_path)
# Predict the language code for each text in texts
langs, _ = lang_model.predict([x.replace("\n", " ") for x in texts])
# Extract the two character language code from the predictions.
return [x[0].split("__")[-1] for x in langs]
def fit(self, X, y):
return self
def transform(self, texts: str) -> List[str]:
# Get the language codes for each text in texts
langs = self.get_language(texts)
# Zip the texts, languages, and their indecies
# sort on the language so that all languages appear together
text_lang_pairs = sorted(
zip(texts, langs, range(len(langs))), key=lambda x: x[1]
)
model = None
translations = []
prev_lang = text_lang_pairs[0]
for text, lang, idx in text_lang_pairs:
if lang == self.target_lang or lang not in self.allowed_langs:
translations.append((idx, text))
else:
# Use the romance model if it is a romance language to avoid
# downloading a model for every language
if lang in self.romance_langs and self.target_lang == "en":
lang = "ROMANCE"
if model is None or lang != prev_lang:
translation_model_name = (
f"Helsinki-NLP/opus-mt-{lang}-{self.target_lang}"
)
# Download the model and tokenizer
model = MarianMTModel.from_pretrained(translation_model_name)
tokenizer = MarianTokenizer.from_pretrained(translation_model_name)
# Tokenize the text
batch = tokenizer.prepare_translation_batch(src_texts=[text])
# Make sure that the tokenized text does not exceed the maximum
# allowed size of 512
batch["input_ids"] = batch["input_ids"][:, :512]
batch["attention_mask"] = batch["attention_mask"][:, :512]
gen = model.generate(**batch)
translations.append(
(idx, tokenizer.batch_decode(gen, skip_special_tokens=True)[0])
)
prev_lang = lang
# Reorganize the translations to match the original ordering
return [x[1] for x in sorted(translations, key=lambda x: x[0])]